
Schedules have always been an integral part of the Radio NZ site. This was always a popular section of site, and it got huge boost when The Listener trimmed its printed listings a few years ago.
Iteration 1
Schedules appeared on our first site in 1998.
The publishing process involved taking a Word document containing a week’s schedule (Saturday to Friday) and posting each day to the site. There was a 3 week cycle with last week, this week and next week. This was done in MS FrontPage.
Iteration 2
The daily schedules were abandoned and replaced with weekly ones because formatting each day’s schedule was too time-consuming. This is how the schedule looked in the site’s last week of existence.

Iteration 3
Our second site was launched in 2003, and was based on a custom PHP CMS. I wrote a parser to take the Word HTML and format it for the web and this was built-in to the CMS for ease of use. The parser could identify the start of each day and added bookmark links at the top of the page automatically.
I also added code to pre-format highlights, classical chart and the weekly music features.
For the first time ever here is the code. Pretty ugly code, but it worked well.
Iteration 4
In Matrix we wanted to again have more granular schedule data, so the parser was rewritten to spit the weekly schedules into days. An import script was written by Squiz to import the XML from this step, creating a page for each day of the schedule and setting the created time of the new page to the day of the schedule.
Forcing the create time of the asset allowed us to show the schedule for the day on the home page of each station – a big leap in functionality. You can see a part of the Matrix asset tree at right.
The new parser (written in PHP) was also able to add linked text for each programme in the schedule. The code was a bit fragile and hard to maintain, so was rewritten as a Rails app. You can review the lastest version of the core parser modules on github.
As a separate web application the generated XML had to be manually uploaded to Matrix, then imported. A minor annoyance, but in all saving a huge amount of time reformatting, creating pages, pasting in content and re-setting the created date on each asset.
I’d estimate that doing all this work by hand would have taken about 6 – 8 hours each week.
For Concert listeners we also would generate a weekly PDF; we had a large number of people contact us after The Listener changes asking for an easy printable format. Quite a number of people go to their local library each week to print these out.
The difficulties with this approach were the inability to change the schedule markup en-mass, problems with programme links being statically coded and only being able to offer 1 font size in the PDF. If there were any late changes we’d have to regenerate the PDF, and some older listeners found the font size too small.
Iteration 5
In ELF we needed to build in new features that we’d want in the next design of the site. These were:
- forward and back navigation by day and week
- automatic generation of PDFs in different sizes
- the ability to display what was on-air at any time.
The section really needed a complete under-the-hood rebuild.
The first task was to rewrite the parser, and integrate it into ELF. And for the first time, testing was used to ensure the code performed as expected. The in-ELF module would provide a single interface for parsing and importing schedules. When the schedule is parsed, the system provides a preview of the data so that we can check it has worked correctly.
Two major changes in this iteration are the splitting of the schedule into events, and dynamic linking of programmes.
The new parser uses contextual clues to work out the date and time of each event in the schedule. These events are imported into ELF as schedule events. Each schedule event is associated with its programme:
belongs_to :programme
The programme association is made based on cues in the text.
The code for the parser is available under an MIT license here, and the core HTML cleaning class here.
Schedule Events look like this in the Rails console:
>> ScheduleEvent.station(Station.national).current_event
+ ELF: Schedule Event
ID : 2474802
Title : Eight to Noon with Bryan Crump
Body : A holiday morning of information and entertainment
Start At : 2011-04-25 08:10:00
Programme : None (National)
Pro Tip: Every model in ELF has a custom inspect method to improve readability during debugging.
The public display routines use the date in the URL (or today for the schedule home page) to collect all the events for that day. These are ordered and sent to the view for formatting. Every schedule event for National and Concert are rendered with the same 8 lines of code. This makes it dead easy to change the markup if we need to (and we will because the site is being redesigned).
The administration section has been optimised for navigating by date, and for editing individual events. Because there is no caching, changes appear on the site immediately.
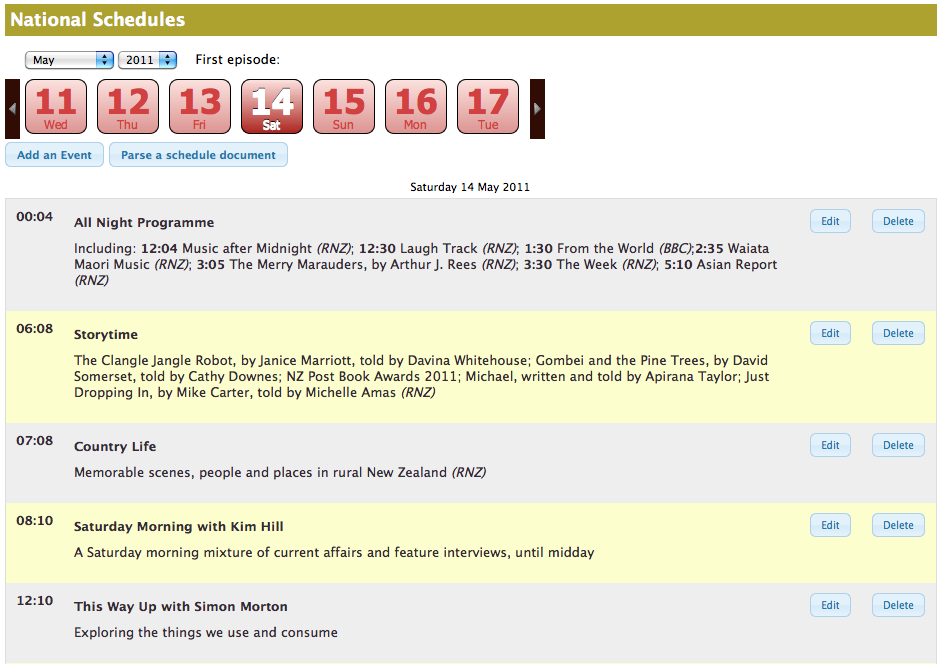
Public schedules page now have forward and back navigation by day or week, and PDFs are dynamically generated on-demand allowing 3 difference size options.
You can append ‘.xml’ to any daily or weekly view to get a dump of that page as XML, and because our schedules are Creative Commons licensed the data can be used subject to a few minor conditions.
Export
Getting the schedules out of Matrix was a breeze via screen scraping. Version 1 of the scraper was given a base URL, and start and end dates in the format yyyymmdd.
The export script grabbed all the historical schedules pages and cached a local copy. The pages were machine generated by the previous parser and almost 100% consistent making it simple to reparse and extract the data.
You can have a look at the scraper code on github.
Our first problem
Schedules are not isolated like recipes – today’s schedule appears on the home page for National and Concert – and at the time both these pages were still running in Matrix. My first solution was to get some javascript to pull the HTML content for this part of the page over from ELF and insert it into the page once it had loaded.
This solution worked, but the 2 second delay before the content appeared looked bad. The second solution was to move these pages into ELF. The content in the right hand column is still generated in Matrix. A cronjob pulls this and other pieces of Matrix content into the ELF database every 2 minutes. Once in the database the content can be used anywhere in ELF. This approach provides a simple way to share content while those sections are still being built.
Recap
At this stage we had Recipes, News, Schedules for National and Concert, and the four main home pages: Site Home, National, Concert and News.
Visitors and Google (webmaster tools) were starting to notice the speed improvement, and we starting to see the benefits of faster administration of pages.
Next time I’ll be covering the provision of data by ELF to the Radio NZ iPhone application.





Leave a comment